Currently, there are more than 6,900 languages worldwide, which is a huge nightmare for researchers of natural language processing. It is quite difficult for researchers to find enough data to train mature models because most languages have little data. Fortunately, many languages share a lot of infrastructures. At the vocabulary level, languages usually have words from the same source. For example, “desk” in English and “Tisch” in German comes from Latin “discus”. Google has released a natural language processing system benchmark called Xtreme. It includes 9 inference tasks for 12 language families and 40 languages.
Gizchina News of the week
Researchers at the technology giant assert that it can evaluate whether artificial intelligence models can learn cross-language knowledge. This will be very useful for more natural language applications. The goal of this benchmark is to promote research in the field of artificial intelligence multilingual learning. In this field, there has been a lot of work to study whether it is possible to use language structures to train reliable machine learning models.
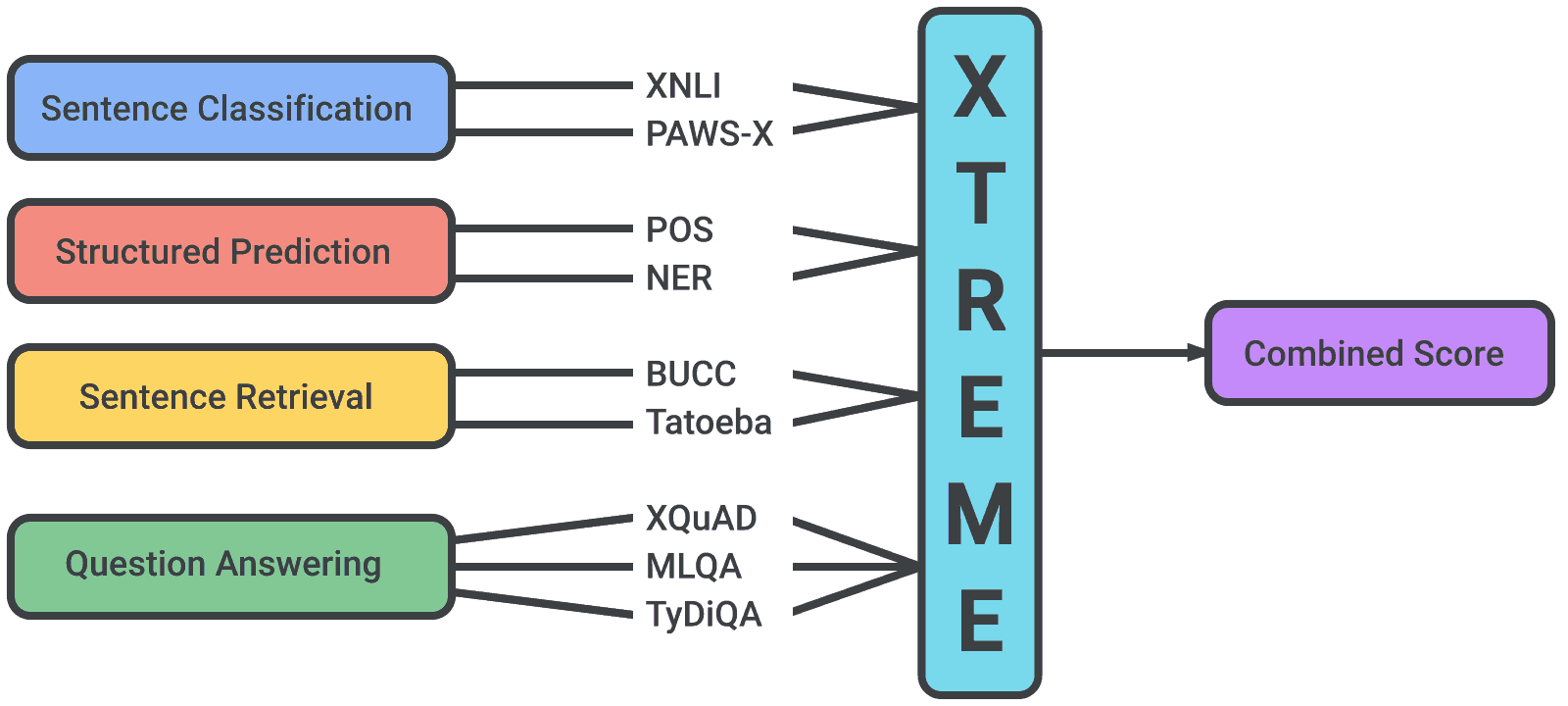
Google XTREME Tasks and Languages
Xtreme was chosen as the benchmark to maximize diversity, expand the coverage of existing tasks, and provide training data. These include some under-studied languages, such as the Tamil language (Tamara language) of southern India, Sri Lanka, and Singapore. Others are the Telugu and Malayalam languages mainly used in southern India, and the Swahili/Yoruba languages of Niger-Congo (Africa).

Xtreme’s 9 tasks cover a series of basic paradigms, including sentence classification (that is, assigning a sentence to one or more classes) and structured prediction (predicting objects such as entities and parts of speech), and sentence retrieval (querying a set of records matching).
Google Research Senior Software Engineer, Melvin Johnson, and DeepMind Scientist, Sebastian Ruder, wrote in a blog post: “We found that although the model performs similar to humans in most existing English tasks, it still performs in many other languages. In general, there is still a huge gap between the performance of English and other languages in the model and simulation environment, which also shows that there is great potential for research on cross-language migration”.