
Microsoft has just unveiled VALL-E (Voice-Aware Language-Learned Encoder-Decoder), a new text-to-speech AI model that can simulate anyone’s voice with just a three-second audio sample. VALL-E is based on Meta’s EnCodec audio compression technology, which employs artificial intelligence to compress high-quality audio to data rates much lower than MP3 files.
Microsoft’s new AI can preserve a speaker’s emotional tone and acoustic environment.
The technology behind VALL-E is groundbreaking, as it allows the model to analyze how a person sounds and then break that information down into discrete components called “tokens.” VALL-E can use this information to match what it “knows” about how that voice would sound if it spoke other phrases besides the three-second sample.
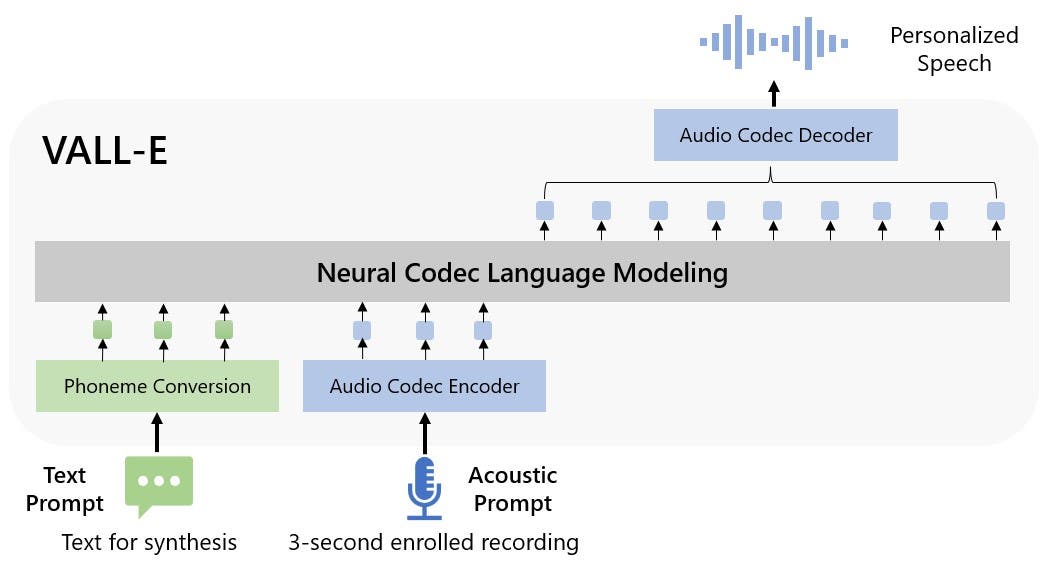
Text-to-speech systems today require high-quality, very clean training data, and it is done in a recording studio with professional equipment. Microsoft has advanced in the field with VALL-E, allowing the model to simulate anyone’s voice using only a three-second sample. VALL-E can now simulate almost anyone’s voice without them having to spend weeks in a studio.
VALL-E’s capabilities were honed using the LibriLight audio library, which contains 60K hours of speech from over 7K speakers. This enables VALL-E to generate realistic-sounding voices in English. When combined with other generative AI models, it has the potential for high-quality text-to-speech applications.
Microsoft has made available a large collection of VALL-E-generated samples, allowing you to hear for yourself. While the results are not perfect, the VALL-E-generated samples sound natural and indistinguishable from the original speaker’s sample.
Despite VALL-impressive E’s capabilities, Microsoft is aware of the technology’s potential for abuse. According to the company, harmful personnel can use audio for malicious purposes such as spoofing voice identification or impersonating. To mitigate these risks, Microsoft suggests developing a detection model to distinguish between synthesized and genuine speech generated by VALL-E.
Finally, VALL-E is a significant advancement in text-to-speech technology. Its ability to simulate anyone’s voice using only a three-second audio sample is revolutionary for various uses. However, Microsoft must continue to improve VALL-E while ensuring that appropriate safeguards are in place to prevent its misuse.



